Blog Index
Insights and articles about knowledge management, information security, technology, data and analytics, business process automation, platform management, and other related topics, from our experienced team of consultants.
Featured Post
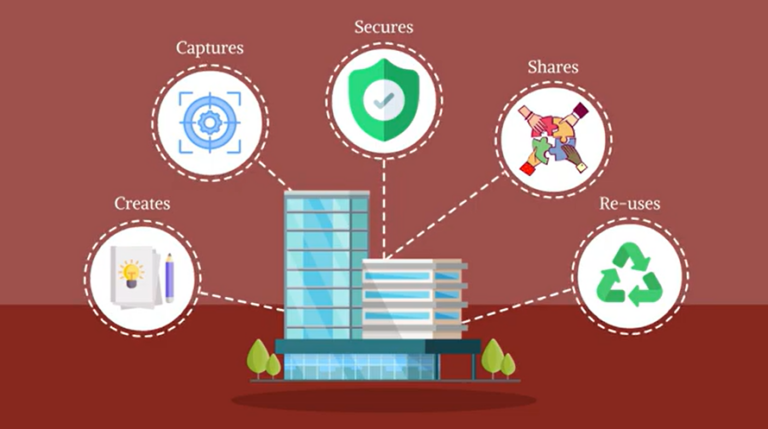
What is Knowledge Management?
Knowledge management is the process of formally creating, capturing, securing, sharing, and re-using an organization’s internal information and knowledge.

As May flowers start to bloom, grow your intranet content for May with some of our favorite topics for this month!

For most organizations, it can be a challenge to balance the need to protect and secure data with the need to promote internal knowledge sharing.

As we welcome the fresh breeze of April into our lives, why not bring a breath of fresh air into your organization's intranet as well?

Knowledge management tips for business leaders

FireOak’s favorite topics for intranet content for March. Adapt these ideas for your organization!

Tactics to showcase and highlight knowledge assets buried in your organization's platforms.

My initial experiences with Copilot, Microsoft's new AI tool embedded directly within the 365 ecosystem.

